Algo muy común en cualquier aplicación Android es el añadir la posibilidad de realizar búsquedas sobre un ListView. Dado que para mostrar los datos sobre un ListView probablemente ya hemos realizado una consulta a la base de datos SQLite donde estos residen, podemos creer que lo mejor es filtrar los datos que ya tenemos cargados en memoria. De esta forma no pagamos de nuevo el precio del acceso a la base de datos que está en disco y es lenta; ni tampoco tenemos que volver a crear los objetos a partir del Cursor que esta nos devuelve. Pero, ¿hemos pensado bien el coste de buscar texto sobre los datos cargados en memoria? ¿Es esto mejor que un acceso a disco? ¿Escala?
La magnitud del problema
Al implementar el filtrado en memoria y optando por una solución sencilla y viable para su desarrollo, descartando el crear grandes estructuras de datos, es tan sencillo como implementar un pequeño bucle que recorra cada elemento y por cada uno realice la búsqueda del texto. Por cada elemento haremos uno o varios contains para buscar la cadena que quiere el usuario sobre el elemento. Esto nos lleva a un problema de O(n*m), dónde n es el número de elementos sobre los que buscar y m es el tamaño de la cadena de texto sobre la que buscar en cada elemento. Esto a priori ya nos da una señal de cómo escala esta solución. Sin embargo, siempre nos puede quedar la duda de, ¿es lo suficientemente buena como para evitar el acceso a la base de datos?
Full text search en SQLite
Full text search es un termino que acuñan casi todos los motores de base de datos para designar a su implementación de la búsqueda de texto. Estos tipos de índices son muy potentes y son capaces de manejar gran cantidad de datos y realizar búsquedas muy diversas en muy poco tiempo. En el caso de SQLite, simplificando mucho, esto se lleva a cabo a través de varias tablas, algunas físicas y otras virtuales que se crean automáticamente para representar las estructuras de datos usadas, entre ellas un árbol B, podéis consultar más detalles técnicos en https://www.sqlite.org/fts3.html.
The search battle
Para comprobar qué método es mejor para realizar las búsquedas, vamos a enfrentarlos y ver qué es mejor, si buscar sobre datos ya cargados en memoria o volver a lanzar la búsqueda a la base de datos. Para ello he creado un proyecto, que tenéis disponible al final del artículo, donde realizar búsquedas sobre distintos conjuntos de datos con distintas palabras clave. Los conjuntos de datos provienen todos del mismo sitio, la lista de coches de Gran Turismo 6. En la comparativa tendremos por un lado la clase MemorySearch, que realiza las búsquedas basándose en el método contains() de esta forma:
@Override
protected List<Car> onSearch(String term) {
ArrayList<Car> results = new ArrayList<Car>();
for(Car car : mCars) {
if(this.contained(term.toLowerCase(),
car.getCountry(),
car.getBrand(),
car.getName(),
String.valueOf(car.getYear()))) {
results.add(car);
}
}
return results;
}
private boolean contained(String term, String... texts) {
for(String text : texts) {
if(text != null && text.contains(term)) {
return true;
}
}
return false;
}
Por otro lado tenemos la clase FTSSearch, que realiza la misma búsqueda contra la base de datos SQLite usando Full text search.
public static final String FTS_QUERY_TEMPLATE = "SELECT * FROM %s WHERE _id IN (SELECT docid FROM %s_fts WHERE content MATCH ?)";
...
@Override
protected List<Car> onSearch(String term) {
Cursor cursor = mDatabase.executeQuery(
mQuery,
new String[]{ term + "*" }
);
return Car.fromCursor(cursor);
}
En ambos casos, el método onSearch() es sobre el que hacemos mediciones. Este método lo ejecutaremos 10 veces para cada conjunto de datos de forma que tengamos una medición algo más estable.
Los conjuntos de datos se distinguen por el número de elementos que contienen, tenemos siete distintos con 10, 100, 250, 500, 750, 1000 y 1200 elementos (el que este último sean 1200 en vez de 1250 no es más que porque GT6 no tiene más coches :-D).
Los resultados que obtenemos, ejecutando la aplicación sobre mi Xperia Z con Android 4.4.2 son los siguientes, si bien haciendo ejecuciones con otras versiones de Android los resultados cambian de magnitud pero, relativamente hablando, son similares entre ellos.
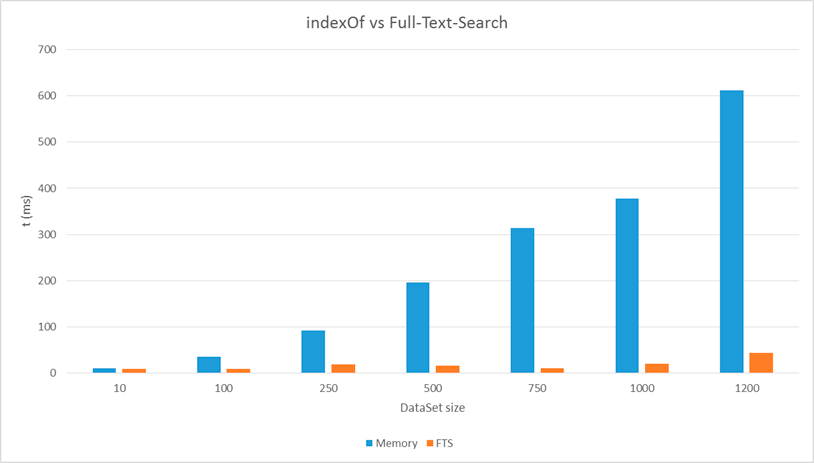 Gráfica comparando los resultados de la batalla
Gráfica comparando los resultados de la batalla
Un claro ganador
Como podéis ver hay un claro ganador y este es la búsqueda con Full text search. A pesar de que haciendo esta búsqueda estamos consultando la base de datos, accediendo a disco y recreando los objetos en cada una de ellas, la velocidad de ejecución es claramente superior. Una solución que además escala muy bien, como podéis ver por la forma de gráfica, en contra de la solución de buscar sobre los datos en memoria.
Evidentemente puedes pensar que si tuviésemos una estructura de datos decente sobre la que buscar, por ejemplo creando ese árbol B, las cosas cambiarían, pero ello requeriría mucho más desarrollo, un mayor consumo de memoria de la aplicación y el tiempo de generación de esa estructura en memoria cada vez que arranque la aplicación o persistir y aumentar aún más la cantidad de código requerido. Viendo el tiempo que tarda una búsqueda con FTS, no tiene sentido ninguno de estos planteamientos alternativos.
FTS no es gratis, evidentemente al crear una tabla de este tipo va a penalizar las escrituras y además incrementará el tamaño de la base de datos en disco, dos cosas que en el 99% de las aplicaciones no serán un gran problema. Lo normal en las aplicaciones móviles es escribir poco y leer muchas veces. Sobre el mayor tamaño en disco de la base de datos, tendrían que ser muchos los datos para ser un problema, unos pocos megas de más cuando los móviles manejan 4-8 GB de almacenamiento como mínimo por norma general no supondrá tampoco un problema.
Así que si vas a desarrollar una app, tienes datos persistidos en una base de datos SQLite, no reinventes la rueda y usa el soporte para Full text search. Si tus datos no se persisten y vienen de la nube, te puedes plantear crear una base de datos SQLite en memoria si no quieres repetir la búsqueda.